
Let's imagine you decided to use the Large Language model in your application. And immediately after taking this decision, you got a lot of questions. Is the selected model suitable for my domain, is it big enough to solve my problem, and where to take the dataset for model fine-tuning. Basically, all these questions can be reduced to the selection of the correct invocation strategy for your model. In this paper, we will try to understand more about these strategies and review them in detail.

Hi there! Today we are going to focus on LLM invocation strategies. If you are still looking for a way to run your first request to the large language model, I recommend checking How to use OpenAI API in Python paper.
Of course, the most effective way would be to train your own LLM from scratch, but for today, it is not a cheap and available option. But it is not a big problem due to the large amount of open-source and commercial models that can completely cover all your needs. So there are 4 main strategies, and let's start to discuss them.
General understanding
As we already discussed, there are 4 main strategies to use LLM. It is 0-shot prompting, few-shot prompting, embedding search, and model fine-tuning. A general algorithm for the selection of the strategy is in the figure below.
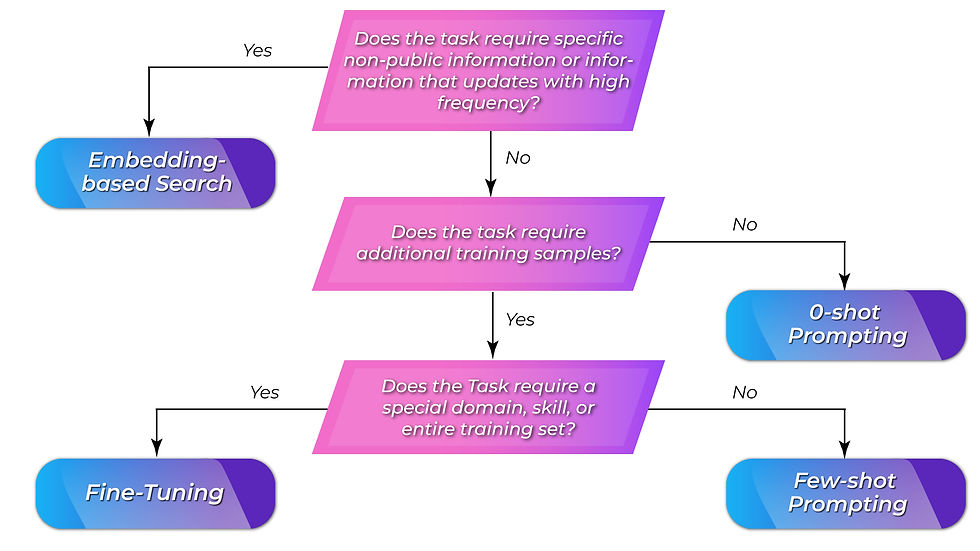
As we can see from the figure, the main question during the approach selection is how unique your problem is. In case it is relatively simple, you can take a simple approach, but if you need to apply complex domain knowledge - with a high probability, you will need to use one of the advanced methods.
The general idea of the 0-shot and few-shot prompting is to use prompt engineering. We will focus on the prompt engineering techniques in the following papers. All you need to know right now, that prompting is some methodology of providing hints to the model to get the desired answer. Let's focus in more detail on each of the strategies.
0-shot prompting
In zero-shot prompting, we are not providing any training samples to the model. The general idea is that the model already has enough knowledge to solve our problem. We just need to specify what we exactly need to get as a result and provide our request.
This approach can be suitable for simple and well-known tasks like Named Entity Recognition (NER), text classification, text generation, translation, summarization, and others.
Let's try to solve the NER problem with 2 classes - CARTOON CHARACTER and FOOD.
Your prompt should be similar to the string below. Remember that this part will be the same from one run of the model to another. In this way, we inform the model that we are going to solve the NER problem.
Identify the entities in the message below and tag them as CARTOON CHARACTER or FOOD. Answer should contain only required entities. Provide only entity and its tag.Now we define our request, the part that contains model input. This part will change from one request to another.
Message: SpongeBob always buys potatoes, tomatoes, oranges and napkins in the shop where Mike Wazowski and David Beckham are working. And finally the answer to our request. As we can see, all entities were classified correctly.
SpongeBob - CARTOON CHARACTER
Mike Wazowski - CARTOON CHARACTER
Potatoes - FOOD
Tomatoes - FOOD
Oranges - FOODLooks like it works good. Of course, you can make a lot of improvements. For instance, you can specify in the initial prompt, how the output should be organized. This will help you to prepare the outputs for other processing steps like we usually do with classical machine learning models.
Few-shot prompting
The general idea of the few-shot prompting is to provide several examples of how the model should behave for the user's request. Usually, it requires no more than 5 samples but depends on the task and situation.
This approach can be really useful for different information extraction tasks, sentiment analysis, relation extraction, and other tasks.
In this case, our prompt will consist of task definition, training shots (samples), and a message like it was in 0-shot prompting. As we can see, we use the same structure but add training samples compared to the previous strategy.
For this tutorial, we are going to solve the Relation Extraction problem.
Please extract all relations from the message below. Please follow the examples. Provide only Entities and Relations for the answer without any other information. We are going to use only 3 samples in this guide. The first line is a text fragment, and the second is our answer in the form of the template for the desired format. This part and task definition will be static for each request.
Examples:
Tom is the brother of Merry.
Entity 1: Tom, Entity 2: Merry, Relation: is brother of.
London is the capital of Great Britain.
Entity 1: London, Entity 2: Great Britain, Relation: is capital of.
Yesterday I met my friend Tommy who was together with Jerry. I didn't know before that Jerry is Tommy's cat.
Entity 1: Tommy, Entity 2: Jerry, Relation: is owner of. Our request will change from one request to another.
Message: I live in Prague. It is the capital of the Czech Republic.Finally, the answer will be exactly what we asked and demonstrated in our 3 samples. Looks like Relation Extraction is working.
Entity 1: Prague, Entity 2: Czech Republic, Relation: is capital of.For both 0-shot and few-shot prompting, we used the ChatGPT model. Please remember that usage of other LLMs may require changes in the prompts. So this part is specific to every model.
Embedding search
The general idea of the embedding search is in the ability of the LLMs to generate answers using some amount of context information. Let's imagine the situation - we have a large amount of super detailed books and news sources about football history and want to build the assistant that will help us to get all information about past football events. In this case, Embedding search will help us.

So what we will do in this case.
Split all our books into small fragments. LLM is a powerful tool but even modern LLMs have input limitations.
Prepare embeddings for each of the fragments. It can be done by a simpler model like BERT.
Prepare the embedding for each question that the user will ask. This action will be done in real-time.
Compare the question's embedding with embeddings extracted from the documents using some measurement (simplest way - cosine distance) and select top N fragments.
Provide these fragments as a context for the model and get the answer to your question.
As we can see we don't need to retrain the LLM model here at all. We just take a pre-trained model and force it to answer using our domain-specific context.
Model fine-tuning
In case for some reason all previous strategies are not working for you - it is the right time to think about model fine-tuning. In general procedure is similar for all other models - we take already trained LLM, take our dataset, and start training until we get acceptable results. The only problem here is that LLMs are super large. A middle-size model with about 40 billion parameters may require 50-100 or sometimes even more GBs of VRAM (GPU memory). It can be partially solved using some optimization techniques (like LoRA), but in any case, the fine-tuning procedure will require a large amount of computational resources.
As you can see, there are a lot of possibilities to use LLMs in your applications. You can easily select the strategy that is more suitable for you.
Thanks for reading this paper, and I hope this information was useful to you! See you soon on new papers in Data Science Factory.
Comments